
Ciągłe zmienne losowe. Metody wyznaczania ciągłej zmiennej losowej. Gęstość prawdopodobieństwa i jej główne właściwości. Prawo rozkładu dyskretnej zmiennej losowej. Przykłady rozwiązywania problemów Określ tabelaryczne metody ustalania prawa dystrybucji za pomocą
„Śmiało mogę przyznać, że ładna bohaterka, uciekająca, może znaleźć się na krętej i niebezpiecznej górskiej ścieżce. Jest mniej prawdopodobne, ale nadal możliwe, że most nad przepaścią zawali się w momencie, gdy postawi na nim stopę. Jest bardzo mało prawdopodobne, że w ostatniej chwili złapie źdźbło trawy i zawiśnie nad przepaścią, ale nawet z taką możliwością mogę się zgodzić. To dość trudne, ale nadal można uwierzyć, że przystojny kowboj właśnie w tym czasie przejdzie i pomoże nieszczęśnikom. Ale żeby w tym momencie pojawił się operator z aparatem, gotowy uwiecznić te wszystkie ekscytujące wydarzenia na kliszy – nie uwierzę, dziękuję!
Niels Bohr o kowbojskich westernach
Jednym z centralnych pojęć teorii prawdopodobieństwa jest pojęcie zmiennej losowej:
Wartość losowa- jest to wartość, która w wyniku testu przyjmie jedną i tylko jedną możliwą wartość, z góry nieznaną i zależną od przyczyn losowych, których nie można z góry wziąć pod uwagę.
Zmienne losowe będziemy oznaczać literami alfabetu łacińskiego X, Y, Z
Zmienna losowa to:
oddzielny
ciągły
mieszane (dyskretne-
ciągły)
Przykład: kostka do gry. Upuszczona liczba to zmienna losowa, która może przyjąć jedną z możliwych wartości — 1, 2, 3, 4, 5 lub 6 z równym prawdopodobieństwem*.

Przykład: wzrost uczniów - wzrost ucznia może przyjąć dowolną wartość z zakresu liczbowego od 1 m do 2,5 m. Liczba możliwych wartości jest nieskończona.

Prawo rozkładu dyskretnej zmiennej losowej
Aby określić dyskretną zmienną losową, nie wystarczy podać wszystkie jej możliwe wartości, należy również wskazać ich prawdopodobieństwo.
Prawo rozkładu dyskretnej zmiennej losowej nazwał korespondencję między możliwymi wartościami zmiennej losowej a prawdopodobieństwem ich wystąpienia.
Prawo rozkładu można określić w formie tabeli, analitycznie (w postaci wzoru) lub graficznie (w postaci wielokąta rozkładu).
Rozważ zmienną losową X, który przyjmuje wartości x 1, x2, x 3 . x n z pewnym prawdopodobieństwem Liczba Pi , gdzie i= 1..n. Suma prawdopodobieństw Liczba Pi równa się 1.

Tabela korelacji wartości zmiennej losowej i ich prawdopodobieństw postaci
nazywa w pobliżu rozkładu dyskretnej zmiennej losowej lub tuż przy dystrybucji. Ta tabela jest najwygodniejszą formą określenia dyskretnej zmiennej losowej.
Graficzna reprezentacja tej tabeli nazywa się wielokąt rozkładu. Możliwe wartości dyskretnej zmiennej losowej są wykreślane wzdłuż osi odciętej, a odpowiadające im prawdopodobieństwa są wykreślane wzdłuż osi rzędnych.

Charakterystyki liczbowe dyskretnych zmiennych losowych
Prawo rozkładu całkowicie charakteryzuje dyskretną zmienną losową. Gdy jednak nie da się określić prawa rozkładu lub nie jest to wymagane, można ograniczyć się do znalezienia wartości, zwanych liczbowymi charakterystykami zmiennej losowej:
- Wartość oczekiwana,
- Dyspersja,
- Odchylenie standardowe
Wielkości te określają pewną wartość średnią, wokół której grupowane są wartości zmiennej losowej oraz stopień ich rozproszenia wokół tej wartości średniej.
Oczekiwanie matematyczne M dyskretna zmienna losowa to średnia wartość zmiennej losowej, równa sumie iloczynów wszystkich możliwych wartości zmiennej losowej i ich prawdopodobieństw.
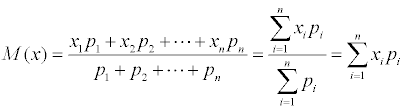
Własności oczekiwań matematycznych:
Aby opisać wiele praktycznie ważnych właściwości zmiennej losowej, trzeba znać nie tylko jej matematyczne oczekiwanie, ale także odchylenie jej możliwych wartości od wartości średniej.
Wariancja zmiennej losowej- miara rozrzutu zmiennej losowej, równa matematycznemu oczekiwaniu kwadratu odchylenia zmiennej losowej od jej matematycznego oczekiwania.
![]()
Biorąc pod uwagę właściwości oczekiwań matematycznych, łatwo wykazać, że
![]()
Wydaje się naturalne, że rozważanie nie kwadratu odchylenia zmiennej losowej od jej matematycznych oczekiwań, ale po prostu odchylenia. Jednak matematyczne oczekiwanie tego odchylenia wynosi zero. Wyjaśnia to fakt, że niektóre możliwe odchylenia są dodatnie, inne ujemne, a w wyniku ich wzajemnego anulowania uzyskuje się zero. Za miarę rozproszenia można by przyjąć matematyczne oczekiwanie modułu odchylenia zmiennej losowej od jej matematycznego oczekiwania, ale z reguły działania związane z wartościami bezwzględnymi prowadzą do kłopotliwych obliczeń.
Właściwości dyspersji:
- Dyspersja stałej wynosi zero.
- Współczynnik stały można usunąć ze znaku dyspersji przez podniesienie go do kwadratu.
- Jeśli x oraz tak niezależnych zmiennych losowych, to wariancja sumy tych zmiennych jest równa sumie ich wariancji.
- a, czyli jeśli k= 1 , wtedy miξ = a,
- jeśli η = cξ , gdzie c jest stała, więc miη = cmiξ ,
- dla dowolnych ξ i η, mi(ξ + η) = miξ + miη .
- jeśli zmienna losowa z prawdopodobieństwem 1 przyjmie wartość a, następnie Dξ = 0,
- jeśli η = cξ , gdzie c jest stała, więc Dη = c 2 Dξ .
- chciałbym mieć równość D(ξ + η) = Dξ + Dη , ale jest to prawdziwe tylko w przypadku niezależnych zmiennych losowych.
Odchylenie standardowe zmienna losowa (czasami termin „ odchylenie standardowe zmiennej losowej „”) nazywa się liczbą równą
Odchylenie standardowe jest zatem, podobnie jak wariancja, miarą rozrzutu rozkładu, ale jest mierzone, w przeciwieństwie do wariancji, w tych samych jednostkach, które są używane do pomiaru wartości zmiennej losowej.
Powtórzenie testów. Formuła Bernoulliego.
Prawdopodobieństwo, że losowy rzut monetą wyląduje do góry nogami, wynosi 1/2. Znając więc prawdopodobieństwo zdarzenia, możemy przewidzieć, że przy stokrotnym rzuceniu monetą herb pojawi się 50 razy? To nie musi być dokładnie 50. Ale coś wokół jest pewne.
 Jacob Bernoulli (1654-1705) rygorystycznie udowodnił, że prawdopodobieństwo zdarzenia ALE przychodzi dokładnie k razy w czasie niepodległości n test jest
Jacob Bernoulli (1654-1705) rygorystycznie udowodnił, że prawdopodobieństwo zdarzenia ALE przychodzi dokładnie k razy w czasie niepodległości n test jest
![]()

gdzie p- prawdopodobieństwo wystąpienia zdarzenia ALE, q to prawdopodobieństwo wystąpienia przeciwnego zdarzenia.
biblioteka flash.narod.ru
Metoda określania dyskretnych zmiennych losowych 736
WIĘCEJ POWIĄZANE MATERIAŁY:
Załóżmy, że interesuje nas dyskretna zmienna losowa X. Aby go w pełni opisać, wystarczy wskazać wszystkie jego możliwe wartości. X 1 , X 2 , . x n(tutaj n jest daną liczbą całkowitą) i prawdopodobieństw R X= x ja>= Liczba Pi, gdzie i = 1, 2, . n z którymi te wartości są akceptowane. Zazwyczaj wszystkie te wartości są rejestrowane w formie tabeli (tabela 3.1).
Tabela nazywa się prawem rozkładu dyskretnej zmiennej losowej (porównaj ją z szeregiem wariacji dyskretnej cechy statystycznej, aby zobaczyć związek między statystyką a teorią prawdopodobieństwa).
Ponieważ dla każdej realizacji tego zestawu warunków zmienna losowa X może wziąć tylko jedną wartość ze zbioru możliwych wartości, wtedy te wartości reprezentują kompletną grupę niekompatybilnych zdarzeń. Następnie, na podstawie wniosku 2 z reguły dodawania prawdopodobieństw, warunek musi być spełniony. Nazywa się to stanem normalizującym.
Graficznie prawo rozkładu dyskretnej zmiennej losowej można przedstawić jako linię łamaną – wielokąt (rys. 3.2) (tu znowu należy przypomnieć szereg wariacyjny).

Ryż. 3.2. Graficzna reprezentacja prawa dystrybucji
Dyskretna zmienna losowa
Jeżeli zbiór możliwych wartości dyskretnej zmiennej losowej jest nieskończony, ale przeliczalny, to prawo rozkładu przyjmie postać (tabela 3.2):
Wykład 1_06: Teoria prawdopodobieństwa. zmienne losowe
W rzeczywistym zastosowaniu teorii prawdopodobieństwa nigdy nie zajmuje się przestrzenią zdarzeń elementarnych. Koncepcja ta jest niezbędna do teoretycznego uzasadnienia schematów probabilistycznych. Najczęściej rozważane są schematy losowe, w których zdarzeniem jest pojawienie się określonej liczby. Dla takich schematów wprowadza się pojęcie zmiennej losowej. Ta koncepcja będzie tematem naszego wykładu. Zastanowimy się nad zmiennymi losowymi, sposobami ich określania (tzw. prawami dystrybucji), charakterystyką numeryczną zmiennych losowych, a także najczęstszymi prawami dystrybucji.
Zmienna losowa to odwzorowanie zbioru zdarzeń elementarnych na zbiór liczb rzeczywistych (lub całkowitych)
Przyjęto następujący schemat: w wyniku losowego eksperymentu wybierane jest jedno ze zdarzeń elementarnych, z niego wyliczana jest wartość funkcji i ta wartość jest obserwowana. Wspomniane mapowanie określa prawdopodobieństwa wystąpienia określonych wartości zmiennej losowej.
Na przykład, niech zbiór zdarzeń elementarnych składa się z dwóch rzutów kostką, co daje 36 elementarnych wyników. Niech funkcja ξ będzie zdefiniowana jako suma wartości wyrzuconych na kostkach. Oczywiście taka zmienna losowa może przyjmować wartości od 2 do 12. W tym przypadku wartość 2 odpowiada jednemu zdarzeniu elementarnemu, a powiedzmy wartości 9 - czterem: (3,6), (4,5), (5,4) oraz (6.3).
Zwykle nie są to zdarzenia elementarne, których zbiór jest nam zupełnie nieznany, ale raczej zmienne losowe, które są obserwowane i badane. Aby ustawić ich zachowanie probabilistyczne, musisz ustawić prawdopodobieństwo, że zmienna losowa przyjmie określoną wartość. Przykład rozważanej przez nas zmiennej losowej możemy zdefiniować następująco:
Spróbuj sporządzić tabelę prawdopodobieństw sumy punktów z trzech rzutów kostką.
Wyznaczenie prawdopodobieństw, z jakimi zmienna losowa przyjmuje swoje wartości, nazywamy jej prawem rozkładu.
Rozkład funkcji zmiennej losowej
Jednym z najważniejszych sposobów ustalenia prawa dystrybucji jest ustalenie funkcji dystrybucji.
Rozkładem zmiennej losowej ξ jest funkcja
 Obrazek przedstawia
Obrazek przedstawia
dystrybuanty zmiennej losowej rozważanej jako przykład.
Dla jasności obszar pod wykresem funkcji jest zacieniowany na szaro. Widać wyraźnie, że funkcja ta jest monotonicznie malejąca i odcinkowo stała. Posiada skoki w punktach odpowiadających wartościom, których prawdopodobieństwo jest dodatnie.
Taka funkcja dystrybucji jest często nazywana całką. Gdy jest ciągła i ma pochodną, to pochodna ta jest często nazywana gęstością rozkładu. Jeśli funkcja rozkładu, jak w naszym przykładzie, jest odcinkowo stała, to zbiór skoków może pełnić rolę gęstości.
Definiowanie dowolnej funkcji dystrybucyjnej jest kłopotliwe. Dla uproszczenia stosowane są dwa podejścia.
Po pierwsze, często można ograniczyć się do bardzo prostych cech liczbowych zmiennej losowej.
Po drugie, często występują klasy rozkładów prawdopodobieństwa i często z pewnych „modelowych” powodów można zrozumieć, do której klasy należy dany rozkład. W takim przypadku wystarczy określić parametry tego rozkładu.
Rozważymy teraz te podejścia.
Charakterystyka zmiennych losowych
Niech zostanie podana zmienna losowa ξ przyjmująca skończoną liczbę wartości a 1 , a 2 , . a k z prawdopodobieństwami
p 1 , p 2 , . p k. Oczekiwanie matematyczne tej zmiennej losowej to suma miξ = Σ i Około 1: k p i a i .
Jak określa się oczekiwanie matematyczne dla bardziej ogólnego przypadku, musisz powiedzieć osobno: używane są całki, ale już nauczono cię, że całka jest definiowana przez sumy całkowite, a dla zmiennych losowych możesz wprowadzić dyskretne zmienne losowe blisko nich , których matematyczne oczekiwania będą odgrywać rolę sum całkowitych dla matematycznych oczekiwań pierwotnej zmiennej losowej.
Oczekiwanie matematyczne, jak widać z tego wzoru, można interpretować jako środek ciężkości zbioru mas p i skoncentrowany w punktach a i. Oczywiście jego właściwości są nam dobrze znane jako właściwości środka ciężkości:
Wariancja zmiennej losowej to matematyczne oczekiwanie kwadratu odchylenia tej zmiennej losowej od jej oczekiwań matematycznych.
Ta definicja na początku wywołuje cichy horror. Właściwie to bardzo wygodne. opis słowny formuły. Słowa matematyczne oczekiwanie oznaczają, że powinniśmy pisać
Dξ = mi (.)
kwadrat wyjaśnia
Dξ = mi (.) 2
odchylenie dotyczy już wyrażenia w nawiasach
Dξ = mi (. − .) 2
zmienna losowa z jej matematycznego oczekiwania kończy pisanie wzoru
Dξ = mi (ξ − miξ) 2
Dyspersję można interpretować jako moment bezwładności tego samego zbioru mas wokół jego środka ciężkości. Jego właściwości są nam również dobrze znane:
Zmienne losowe ξ i η nazywane są niezależnymi, jeśli dla dowolnego a oraz b niezależne wydarzenia
Łatwo to zauważyć, jeśli zsumujemy n niezależne i identycznie rozłożone zmienne losowe z oczekiwaniem matematycznym a i dyspersja b, to dla ich sumy matematyczne oczekiwanie i wariancja są odpowiednio: n a oraz nb, a dla średniej arytmetycznej - odpowiednio a oraz b/n .
Jeśli więc chcemy oszacować jakąś liczbę, która jest matematycznym oczekiwaniem jakiejś zmiennej losowej, możemy zorganizować test losowy - obserwować tę zmienną losową wiele razy i obliczyć średnią arytmetyczną. Jego rozrzut wokół prawdziwej wartości będzie malał wraz ze wzrostem liczby obserwacji: jeśli zmierzysz go sto razy, zmniejszy się on dziesięciokrotnie (ponieważ to nie sama dyspersja jest ważna, ale jej źródło). Ten fakt leży u podstaw ważnej metody obliczeniowej modelowania statystycznego.
Należy zauważyć, że przez analogię do zdarzeń losowych można rozróżnić zmienne losowe wzajemnie niezależne i niezależne w parach. Dla wspomnianej własności wariancji wystarczy, że zmienne losowe są parami niezależne. Wykorzystywane są inne cechy, ale te są najważniejsze. Teraz rozważymy kilka ważnych typów rozkładów i za każdym razem wskażemy ich matematyczne oczekiwanie.
Rodzaje dystrybucji
Równomierna dystrybucja
Zmienna losowa jest rozłożona równomiernie w przedziale [ a,b] , gdzie a jeśli jego funkcja dystrybucji
F(x) jest równe 0 dla x, 1 w x > b i zmienia się liniowo od 0 do 1 at a .
(a + b)/2 , a wariancja to ( b − a) 2 /12 .
 Rysunek przedstawia wykres tej funkcji rozkładu dla a= 0 i b = 1 .
Rysunek przedstawia wykres tej funkcji rozkładu dla a= 0 i b = 1 .
To prawo rozkładu jest dla nas bardzo ważne, ponieważ wszystkie standardowe komputerowe czujniki zmiennych losowych (liczby pseudolosowe) modelują właśnie takie zmienne losowe, az nich tworzone są potrzebne nam zmienne losowe.
rozkład wykładniczy
Zmienna losowa ma rozkład wykładniczy lub wykładniczy, jeśli jest nieujemna i F(x) = 1 − exp(−λ x) , gdzie λ jest stałą dodatnią.
Matematyczne oczekiwanie takiej zmiennej losowej to λ − 1 , a wariancja to λ − 2 .
 Rysunek przedstawia wykres tej funkcji rozkładu dla λ = 3.
Rysunek przedstawia wykres tej funkcji rozkładu dla λ = 3.
Często spotykamy się z tym prawem dystrybucji w zastosowaniach, zwłaszcza w inżynierii radiowej i komunikacji. W szczególności często zakłada się, że czas rozmowy dwóch abonentów jest rozłożony zgodnie z prawem wykładniczym.
Normalna dystrybucja
Jest to najpopularniejszy ze standardowych rozkładów prawdopodobieństwa i na pierwszy rzut oka może wydawać się dziwne, że tak złożona formuła występuje najczęściej.
Zmienna losowa ma rozkład normalny lub według Gaussa if (po prawej stronie jest portret K.F. Gaussa (1777-1855))


Ta funkcja zależy od parametrów a i σ. Matematyczne oczekiwanie takiej zmiennej losowej wynosi a, a wariancja wynosi σ 2 .

Wykres przedstawia standardową funkcję z a= 0 i σ = 1 .
Powodem częstego występowania tego prawa w aplikacjach jest to, że przy dodawaniu zmiennych losowych rozkład ich sumy, rozpatrywany jako zmienna losowa, bardzo często zbliża się do normalnego.
Nie wystąpi w naszych zadaniach, ale byłoby nieprzyzwoite o tym nie wspominać.
Dystrybucja Bernoulliego
 Ta najprostsza dyskretna dystrybucja nosi imię szwajcarskiego matematyka Jakuba Bernoulliego Starszego (1654-1705), (był też młodszy, który pracował w Petersburgu).
Ta najprostsza dyskretna dystrybucja nosi imię szwajcarskiego matematyka Jakuba Bernoulliego Starszego (1654-1705), (był też młodszy, który pracował w Petersburgu).
Zmienna losowa ma rozkład Bernoulliego, jeśli przyjmuje tylko dwie wartości. Zwykle wartości te wynoszą 1, prawdopodobieństwo, że p ,
i 0, których prawdopodobieństwo jest równe q = 1 − p.
Matematyczne oczekiwanie takiej zmiennej losowej wynosi p, a wariancja to pq .
Oczywiście sam zbudujesz taki harmonogram.
Prawo Bernoulliego jest bardzo wygodne dla wszelkiego rodzaju konstrukcji modeli, jest tylko trochę bardziej skomplikowane niż jego szczególny przypadek - rzucanie monetą, gdzie p = 1/2 .
Rozkład dwumianowy
Zmienna losowa ξ równa sumie n niezależne identyczne zmienne losowe Bernoulliego mają rozkład dwumianowy. Dla niej
Matematyczne oczekiwanie takiej zmiennej losowej wynosi np, a wariancja to npq .
 Rozkład dwumianowy z rosnącą liczbą wyrazów n staje się bardzo podobny do rozkładu normalnego.
Rozkład dwumianowy z rosnącą liczbą wyrazów n staje się bardzo podobny do rozkładu normalnego.
Trzeba tylko znormalizować zmienną losową w odpowiedni sposób: odjąć oczekiwanie matematyczne i podzielić przez pierwiastek wariancji, tj. zamiast ξ, rozważ
η = (ξ — np)(npq) − 1/2 .
Jeśli ze wzrostem n prawdopodobieństwo p zmniejsza się i w taki sposób, aby produkt został zachowany lub ustabilizowany np otrzymujemy kolejną klasyczną dystrybucję, którą teraz opiszemy.
Rozkład Poissona
 Podział ten został zaproponowany przez francuskiego matematyka Siméona Poissona (1781-1840), honorowego członka Akademii Nauk w Petersburgu.
Podział ten został zaproponowany przez francuskiego matematyka Siméona Poissona (1781-1840), honorowego członka Akademii Nauk w Petersburgu.
Zmienna losowa ξ ma rozkład Poissona, jeśli
Matematyczne oczekiwanie takiej zmiennej losowej to λ, a wariancja również to λ.

Rozkład Poissona jest typowy dla schematu zdarzeń rzadkich – w którym występuje wiele zmiennych losowych o rozkładzie Bernoulliego i bardzo małe prawdopodobieństwo pozytywnego wyniku dla każdego z nich.
Na przykład zauważono, że liczba liter wrzuconych do skrzynki pocztowej z nieoznaczoną kopertą ma rozkład Poissona.
Ćwiczenia
- Zmienna losowa przyjmuje wartości 0 z prawdopodobieństwem 0,3, 2 z prawdopodobieństwem 0,2, 4 z prawdopodobieństwem 0,5. Znajdź jego matematyczne oczekiwanie i wariancję.
Dwie zmienne losowe mają matematyczne oczekiwanie równe 0 i wariancję 1. W jakim stopniu może zmienić się wariancja ich sumy. Zbuduj przykład z największą i najmniejszą wartością wariancji sumy.
Pytania egzaminacyjne
Zmienne losowe i ich dystrybuanty.
Matematyczne oczekiwanie i rozproszenie. Ich właściwości.
www.math.spbu.ru
Blog edukacyjny - wszystko do nauki
Powtórzenie eksperymentów
Na praktyczne zastosowanie Teoria prawdopodobieństwa często ma do czynienia z problemami, w których ten sam eksperyment lub podobne eksperymenty są powtarzane więcej niż raz. W wyniku każdego eksperymentu pewne zdarzenie A może pojawić się lub nie, i nie jesteśmy zainteresowani wynikiem każdego indywidualnego eksperymentu, ale całkowitą liczbą wystąpień zdarzenia A w wyniku serii eksperymentów. W takich problemach wymagana jest umiejętność określenia prawdopodobieństwa dowolnej liczby przejawów zdarzenia w wyniku serii eksperymentów. Są one rozwiązywane po prostu w przypadku, gdy eksperymenty są niezależne.
Kilka eksperymentów nazywa się niezależnymi, jeśli prawdopodobieństwo takiego lub innego wyniku każdego z eksperymentów nie zależy od wyników innych eksperymentów.
Niezależne eksperymenty mogą być przeprowadzane w tym samym lub różne warunki. W pierwszym przypadku prawdopodobieństwo zdarzenia A we wszystkich eksperymentach jest takie samo Р i (А)=const. W drugim przypadku prawdopodobieństwo zdarzenia A zmienia się z doświadczenia na doświadczenie Р i (А)=var. Pierwszy przypadek to konkretne twierdzenie, a drugi to ogólne twierdzenie o powtarzaniu eksperymentów.
Sformułowanie konkretnego twierdzenia o powtórzeniu eksperymentów:
Jeżeli przeprowadza się n niezależnych eksperymentów, w każdym z których zdarzenie A zachodzi z prawdopodobieństwem p, to prawdopodobieństwo, że zdarzenie A wystąpi dokładnie m razy wyraża się wzorem:
gdzie q = 1 - p, C n m to liczba wszystkich kombinacji, tj. liczba sposobów, w jakie można wybrać m spośród n eksperymentów, w których zaszło zdarzenie A.
Ogólny wzór na twierdzenie:
gdzie z jest dowolnym parametrem.
Zarówno ogólnie, jak i w konkretnym przypadku:
Zmienne losowe i prawa ich rozkładu
Zmienna losowa to wielkość, która w wyniku eksperymentu może przyjąć taką lub inną wartość, z góry nie wiadomo która.
Zmienne losowe są dwojakiego rodzaju:
ciągły;
nieciągły (dyskretny).
W przyszłości umówmy się na oznaczenie zmiennych losowych dużymi literami, a ich możliwych wartości odpowiednimi małymi literami.
Przykład:
X to liczba trafień trzema strzałami:
x 1 = 0;
x 2 = 1;
x 3 = 2;
x 4 = 3.
Rozważmy nieciągłą zmienną losową X o możliwych wartościach x 1 , x 2 , …, x n . Każda z tych wartości jest możliwa, ale nie pewna, a wartość X może przyjąć każdą z nich z pewnym prawdopodobieństwem
X \u003d x 1;
X \u003d x 2;
X \u003d x 3;
X \u003d x 4.
∑P m,n = 1, ponieważ zdarzenia niezgodne tworzą kompletną grupę. To całkowite prawdopodobieństwo rozkłada się w jakiś sposób na poszczególne wartości. Zmienna losowa zostanie w pełni opisana z probabilistycznego punktu widzenia, jeśli dany rozkład zostanie podany, tj. podane jest dokładne prawdopodobieństwo każdego zdarzenia. To ustanawia tzw. prawo rozkładu zmiennej losowej.
Prawo rozkładu zmiennej losowej Nazywa się każdą relację, która ustanawia związek między możliwymi wartościami zmiennej losowej a odpowiadającymi im prawdopodobieństwami.
Prawo rozkładu nieciągłej zmiennej losowej X można podać w postaci:
tabelaryczny;
analityczny;
graficzny.
Najprostszą formą ustalenia prawa rozkładu nieciągłej zmiennej losowej X jest tabela.
zmienne losowe. Dyskretna zmienna losowa.
Wartość oczekiwana
Druga sekcja na teoria prawdopodobieństwa dedykowane zmienne losowe , który niewidocznie towarzyszył nam dosłownie w każdym artykule na ten temat. I nadszedł czas, aby jasno wyartykułować, co to jest:
Losowy nazywa wartość, które w wyniku testu podejmie jeden i tylko jeden wartość liczbowa, która zależy od czynników losowych i nie można jej przewidzieć z góry.
Zmienne losowe to zazwyczaj wyznaczyć poprzez * , a ich wartości w odpowiednich małych literach z indeksami dolnymi, na przykład .
* Czasami używane razem z literami greckimi
Natknęliśmy się na przykład na pierwsza lekcja z teorii prawdopodobieństwa, gdzie faktycznie wzięliśmy pod uwagę następującą zmienną losową:
- ilość punktów, które wypadną po rzuceniu kostką.
Wynikiem tego testu będzie jeden jedyny linia, której nie da się przewidzieć (sztuczki nie są brane pod uwagę); w tym przypadku zmienna losowa może przyjąć jedną z następujących wartości:
- liczba chłopców na 10 noworodków.
Jest całkiem jasne, że liczba ta nie jest z góry znana, a u kolejnych dziesięciu urodzonych dzieci może być:
Albo chłopcy - jeden i tylko jeden z wymienionych opcji.
A żeby zachować formę, trochę wychowania fizycznego:
- odległość skoku w dal (w niektórych jednostkach).
Nawet mistrz sportu nie jest w stanie tego przewidzieć 🙂
Jakie są jednak Twoje hipotezy?
Jak tylko zbiór liczb rzeczywistych nieskończona, to zmienna losowa może trwać nieskończenie wiele wartości z pewnego przedziału. I to jest jego zasadnicza różnica w stosunku do poprzednich przykładów.
Zatem, wskazane jest podzielenie zmiennych losowych na 2 duże grupy:
1) Dyskretny (przerywany) zmienna losowa - przyjmuje oddzielnie brane, wyodrębnione wartości. Liczba tych wartości na pewno lub nieskończona, ale policzalna.
... narysowano niezrozumiałe terminy? Pilnie powtórz podstawy algebry!
2) Ciągła zmienna losowa - trwa wszystko wartości liczbowe z pewnego skończonego lub nieskończonego zakresu.
Notatka : skróty DSV i NSV są popularne w literaturze edukacyjnej
Najpierw przeanalizujmy dyskretną zmienną losową, a następnie - ciągły.
Prawo rozkładu dyskretnej zmiennej losowej
- Ten konformizm między możliwymi wartościami tej wielkości a ich prawdopodobieństwami. Najczęściej prawo zapisane jest w tabeli: 
Termin jest dość powszechny wiersz
dystrybucja, ale w niektórych sytuacjach brzmi to niejednoznacznie, dlatego będę się trzymać „prawa”.
I teraz bardzo ważny punkt
: ponieważ zmienna losowa koniecznie zaakceptuje jedna z wartości, a następnie forma odpowiednich zdarzeń pełna grupa a suma prawdopodobieństw ich wystąpienia jest równa jeden:
lub, jeśli jest napisane złożone:
Na przykład prawo rozkładu prawdopodobieństw punktów na kostce ma następującą postać: 
Możesz odnieść wrażenie, że dyskretna zmienna losowa może przyjmować tylko „dobre” wartości całkowite. Rozwiejmy iluzję - mogą być cokolwiek:
Niektóre gry mają następujące przepisy dotyczące dystrybucji wypłat: 
…prawdopodobnie od dawna marzyłeś o takich zadaniach 🙂 Zdradzę Ci sekret – ja też. Zwłaszcza po zakończeniu pracy nad teoria pola.
Decyzja: ponieważ zmienna losowa może przyjąć tylko jedną z trzech wartości, odpowiednie zdarzenia tworzą pełna grupa, co oznacza, że suma ich prawdopodobieństw jest równa jeden: ![]()
Demaskujemy „partyzanta”: ![]()
– tym samym prawdopodobieństwo wygrania jednostek konwencjonalnych wynosi 0,4.
Kontrola: czego potrzebujesz, aby się upewnić.
Odpowiedź:
Nierzadko zdarza się, że prawo dystrybucji musi być opracowane niezależnie. Do tego celu klasyczna definicja prawdopodobieństwa, twierdzenia o mnożeniu / dodawaniu dla prawdopodobieństw zdarzeń i inne żetony tervera:
Pudełko zawiera 50 losy na loterię, wśród których jest 12 zwycięskich, a 2 z nich wygrywają po 1000 rubli, a reszta - po 100 rubli. Opracuj prawo podziału zmiennej losowej - wielkości wygranej, jeśli jeden los zostanie losowo wylosowany z pudełka.
Decyzja: jak zauważyłeś zwyczajowo umieszcza się wartości zmiennej losowej w rosnąco. Dlatego zaczynamy od najmniejszych wygranych, a mianowicie rubli.
Łącznie jest 50 - 12 = 38 takich biletów i według klasyczna definicja:
to prawdopodobieństwo, że losowo wylosowany los nie wygra.
Reszta spraw jest prosta. Prawdopodobieństwo wygrania rubli wynosi:
I dla :
Sprawdzanie: - a to szczególnie przyjemny moment takich zadań!
Odpowiedź: wymagane prawo dystrybucji wypłat: ![]()
Następujące zadanie do samodzielnej decyzji:
Prawdopodobieństwo, że strzelec trafi w cel wynosi . Stwórz prawo rozkładu dla zmiennej losowej - liczby trafień po 2 strzałach.
…Wiedziałem, że za nim tęskniłeś 🙂 Pamiętamy twierdzenia o mnożeniu i dodawaniu. Rozwiązanie i odpowiedź na końcu lekcji.
Prawo rozkładu całkowicie opisuje zmienną losową, ale w praktyce przydatne (a czasem bardziej przydatne) jest poznanie tylko jej części. cechy liczbowe .
Matematyczne oczekiwanie dyskretnej zmiennej losowej Jakie jest probabilistyczne znaczenie uzyskanego wyniku? Jeśli rzucisz kostką wystarczająco dużo razy, to oznaczać spadające punkty będą bliskie 3,5 - a im więcej zrobisz testów, tym bliżej. Właściwie już szczegółowo o tym efekcie mówiłem w lekcji o prawdopodobieństwo statystyczne.
Przypomnijmy sobie teraz naszą hipotetyczną grę:

Powstaje pytanie: czy w ogóle opłaca się grać w tę grę? ... kto ma jakieś wrażenia? Więc nie możesz powiedzieć „od ręki”! Ale na to pytanie można łatwo odpowiedzieć, obliczając matematyczne oczekiwanie, w istocie - Średnia ważona prawdopodobieństwa wygranej:
Tak więc matematyczne oczekiwanie tej gry przegrywający.
Nie ufaj wrażeniom - ufaj liczbom!
Tak, tutaj można wygrać 10, a nawet 20-30 razy z rzędu, ale na dłuższą metę nieuchronnie zostaniemy zrujnowani. I nie radziłbym grać w takie gry 🙂 No, może tylko dla zabawy.
Z powyższego wynika, że oczekiwanie matematyczne NIE jest wartością LOSOWĄ.
Twórcze zadanie do samodzielnych badań:
Pan X gra w europejską ruletkę według następującego systemu: stale obstawia 100 rubli na czerwone. Ułóż prawo rozkładu zmiennej losowej - jej wypłatę. Oblicz matematyczne oczekiwanie wygranych i zaokrąglij je do kopiejek. Jak dużo przeciętny czy gracz przegrywa za każde sto zakładu?
Odniesienie
: Ruletka europejska zawiera 18 czerwonych, 18 czarnych i 1 zielony sektor („zero”). W przypadku wypadnięcia „czerwonego” gracz otrzymuje podwójny zakład, w przeciwnym razie trafia do dochodu kasyna
Istnieje wiele innych systemów gry w ruletkę, dla których możesz stworzyć własne tabele prawdopodobieństwa. Ale tak jest w przypadku, gdy nie potrzebujemy żadnych praw i tabel dystrybucji, ponieważ jest pewne, że matematyczne oczekiwania gracza będą dokładnie takie same. Tylko zmiany z systemu na system dyspersja, o czym dowiemy się w części 2 lekcji.
Ale wcześniej warto rozciągnąć palce na klawiszach kalkulatora:
Zmienna losowa jest określona przez własne prawo rozkładu prawdopodobieństwa:

Sprawdź, czy wiadomo, że . Przeprowadź kontrolę.
Następnie zwracamy się do gabinetu rozproszenie dyskretnej zmiennej losowej, a jeśli to możliwe,
Co obejmuje badanie lekarskie (zgodnie z zarządzeniem 302n) Podczas przeprowadzania badania lekarskiego zgodnie z zarządzeniem nr 302n każdy musi przejść: analizę kliniczną moczu; […] Państwowy program pomocy w dobrowolnym przesiedleniu do Federacji Rosyjskiej rodaków mieszkających za granicą Przewodnik krok po kroku dla uczestników Państwowego […] Ustalamy, jaka powinna być wysokość emerytury minimalnej dla osoby niepełnosprawnej z grupy 2. Teraz państwo na różne sposoby udziela pomocy niechronionym społecznie segmentom społeczeństwa. Specjalna opieka […]
Podstawowe dystrybucje
zmienne losowe
Wytyczne dla niezależna praca studenci
wszystkie formy edukacji
Opracowane przez V.A. Bobkowa
Iwanowo 2005
Opracowane przez V.A. Bobkowa
Podstawowe rozkłady zmiennych losowych: Wytyczne do samodzielnej pracy uczniów wszystkich form kształcenia / Oddz. VA Bobkova; GOUVPO Iwan. stan chemiczno-technologiczna nie-t. - Iwanowo, 2005. 32 s.
Wskazówki metodyczne poświęcone są jednemu z ważnych działów kursu „Teoria prawdopodobieństwa i statystyka matematyczna”, a mianowicie: głównym rozkładom zmiennych losowych. Podano pojęcie zmiennej losowej, opisano metody wyznaczania dyskretnych i ciągłych zmiennych losowych, podano definicje matematycznego oczekiwania, wariancji, odchylenia standardowego. Dalej rozważane są główne rozkłady dyskretnych zmiennych losowych: rozkład Bernoulliego, rozkład dwumianowy, rozkład Poissona, rozkłady geometryczne i hipergeometryczne, a także główne rozkłady ciągłych zmiennych losowych: jednostajny, wykładniczy, rozkład normalny. Wyprowadzono wzory na numeryczne charakterystyki rozpatrywanych rozkładów, podano ilustracje graficzne i przykłady rozwiązywania problemów. Podano zadania do samodzielnego rozwiązania.
Instrukcje metodyczne przeznaczone są do samodzielnej pracy studentów wszystkich specjalności uczelni.
Bibliografia: 4 tytuły.
Recenzent Doktor nauk technicznych, prof. A. N. Labutin
(Państwowy Uniwersytet Technologii Chemicznej w Iwanowie)
Podstawowe informacje o zmiennych losowych
Pojęcie zmiennej losowej
Losowy nazywają wartość, która w wyniku testu przyjmie jedną i tylko jedną możliwą wartość, nieznaną z góry i zależną od przyczyn losowych, których nie można brać pod uwagę.
Zmienne losowe są oznaczone wielką łaciną litery X,Y, Z, …, a ich możliwe wartości to odpowiadające im małe litery x, y, z, … .
Przykłady zmiennych losowych:
1) liczbę połączeń odebranych od abonentów centrali telefonicznej w określonym czasie;
2) masę ziarna pszenicy pobranego losowo;
3) liczbę ocen doskonałych uczniów jednej grupy z egzaminu;
4) odległość od miejsca rzucenia dyskiem do miejsca upadku;
5) liczbę błędów drukarskich w księdze.
Różnorodność zmiennych losowych jest duża. Liczba przyjmowanych przez nich wartości może być skończona, policzalna lub niepoliczalna; wartości te mogą być ułożone dyskretnie lub interwały wypełnienia (skończone lub nieskończone).
Dyskretne zmienne losowe - są to zmienne losowe, które mogą przyjmować tylko skończony lub policzalny zbiór wartości. Na przykład liczba wystąpień herbu w pięciu rzutach monetą (możliwe wartości to 0, 1, 2, 3, 4, 5); liczba strzałów przed pierwszym trafieniem w tarczę (możliwe wartości to 1, 2, ..., n, gdzie n to liczba dostępnych nabojów); liczba uszkodzonych elementów w urządzeniu składającym się z trzech elementów (możliwe wartości 0, 1, 2, 3) są dyskretnymi zmiennymi losowymi.
Ciągłe zmienne losowe to zmienne losowe, których możliwe wartości tworzą pewien skończony lub nieskończony przedział. Np. uptime urządzenia, zasięg pocisku, czas oczekiwania na autobus to ciągłe zmienne losowe.
Metody ustalania zmiennych losowych
Aby ustawić zmienną losową, musisz znać wartości, jakie może przyjąć, oraz prawdopodobieństwa, z jakimi zmienna losowa przyjmuje swoje wartości. Dowolna reguła (tabela, funkcja, wykres) pozwalająca na znalezienie prawdopodobieństw poszczególnych wartości zmiennej losowej lub zbioru tych wartości nazywana jest losowe prawo rozkładu zmiennej (lub po prostu dystrybucja ). O zmiennej losowej mówią, że „podlega ona danemu prawu rozkładu”.
Niech X będzie dyskretną zmienną losową, która przyjmuje wartości (zbiór tych wartości jest skończony lub policzalny) z pewnymi prawdopodobieństwami ![]() . Prawo rozkładu dyskretnej zmiennej losowej
wygodny do ustawienia za pomocą formuły
. Prawo rozkładu dyskretnej zmiennej losowej
wygodny do ustawienia za pomocą formuły ![]() i = 1, 2, 3, … , n, … , co określa prawdopodobieństwo, że w wyniku eksperymentu zmienna losowa X przyjmie wartość . Dla dyskretnej zmiennej losowej prawo rozkładu można podać jako stoły dystrybucyjne
:
i = 1, 2, 3, … , n, … , co określa prawdopodobieństwo, że w wyniku eksperymentu zmienna losowa X przyjmie wartość . Dla dyskretnej zmiennej losowej prawo rozkładu można podać jako stoły dystrybucyjne
:
| X | … | … | |||
| P | … | p n | … |
Tutaj pierwsza linia zawiera wszystkie możliwe wartości (zwykle w porządku rosnącym) zmiennej losowej, a druga - ich prawdopodobieństwa. Taki stół nazywa się w pobliżu dystrybucji .
Ponieważ zdarzenia są niezgodne i tworzą kompletną grupę zdarzeń, suma ich prawdopodobieństw jest równa jedności.
Prawo rozkładu dyskretnej zmiennej losowej można określić graficznie, jeśli możliwe wartości zmiennej losowej wykreślone są na osi odciętej, a ich prawdopodobieństwa na osi rzędnych. Linia przerywana łącząca kolejno uzyskane punkty nazywa się wielokąt rozkładu .
Oczywiście szereg rozkładów można skonstruować tylko dla dyskretnych zmiennych losowych. Dla ciągłych zmiennych losowych nie można nawet wyliczyć wszystkich możliwych wartości.
Uniwersalnym sposobem określenia prawa rozkładu prawdopodobieństwa, odpowiednim zarówno dla dyskretnych, jak i ciągłych zmiennych losowych, jest jego funkcja dystrybucyjna.
Niech X będzie zmienną losową, x - prawdziwy numer. Rozkład prawdopodobieństwa zmiennej losowej X nazywamy prawdopodobieństwem, że ta zmienna losowa przyjmie wartość mniejszą niż x:
![]() (1)
(1)
Geometrycznie równość tę można interpretować w następujący sposób: F(x) jest prawdopodobieństwem, że zmienna losowa X przyjmie wartość, którą na osi rzeczywistej przedstawia punkt na lewo od punktu x, czyli że losowy punkt X wpadnie w przedział .
Właściwości funkcji dystrybucji:
1. Wartości funkcji rozkładu należą do segmentu:
2. F(x) jest funkcją niemalejącą, tj. ![]() jeśli .
jeśli .
Wniosek 1. Prawdopodobieństwo, że zmienna losowa przyjmie wartość zawartą w przedziale )